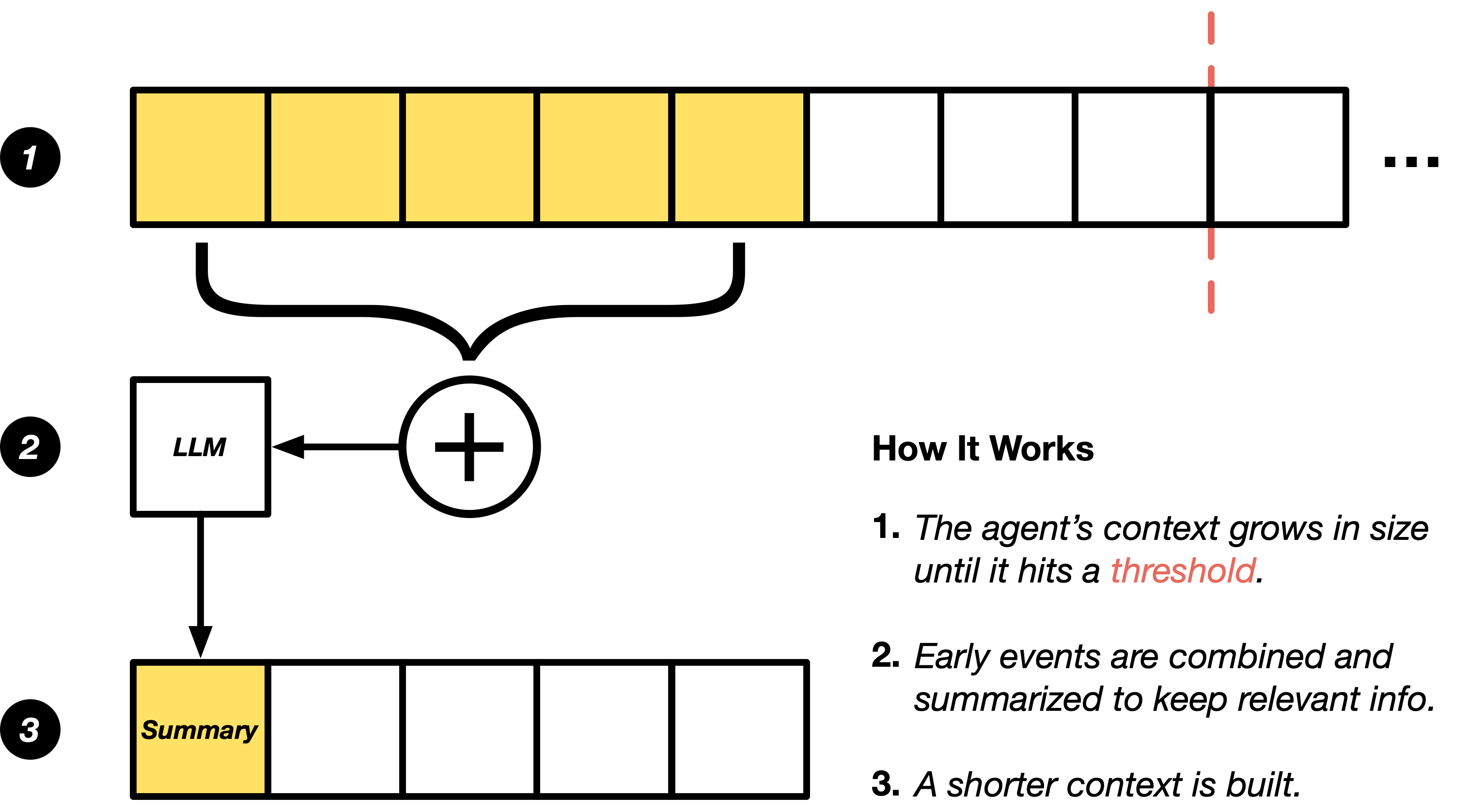
A context condenser is a crucial component that addresses one of the most persistent challenges in AI agent development: managing growing conversation context efficiently. As conversations with AI agents grow longer, the cumulative history leads to:
💰 Increased API Costs: More tokens in the context means higher costs per API call
⏱️ Slower Response Times: Larger contexts take longer to process
📉 Reduced Effectiveness: LLMs become less effective when dealing with excessive irrelevant information
The context condenser solves this by intelligently summarizing older parts of the conversation while preserving essential information needed for the agent to continue working effectively.
OpenHands SDK provides LLMSummarizingCondenser as the default condenser implementation. This condenser uses an LLM to generate summaries of conversation history when it exceeds the configured size limit.
The LLMSummarizingCondenser extends the RollingCondenser base class, which provides a framework for condensers that work with rolling conversation history. You can create custom condensers by extending base classes (source code):
RollingCondenser - For condensers that apply condensation to rolling history
CondenserBase - For more specialized condensation strategies
This architecture allows you to implement custom condensation logic tailored to your specific needs while leveraging the SDK’s conversation management infrastructure.
"""To manage context in long-running conversations, the agent can use a context condenserthat keeps the conversation history within a specified size limit. This exampledemonstrates using the `LLMSummarizingCondenser`, which automatically summarizesolder parts of the conversation when the history exceeds a defined threshold."""import osfrom pydantic import SecretStrfrom openhands.sdk import ( LLM, Agent, Conversation, Event, LLMConvertibleEvent, get_logger,)from openhands.sdk.context.condenser import LLMSummarizingCondenserfrom openhands.sdk.tool import Toolfrom openhands.tools.file_editor import FileEditorToolfrom openhands.tools.task_tracker import TaskTrackerToolfrom openhands.tools.terminal import TerminalToollogger = get_logger(__name__)# Configure LLMapi_key = os.getenv("LLM_API_KEY")assert api_key is not None, "LLM_API_KEY environment variable is not set."model = os.getenv("LLM_MODEL", "anthropic/claude-sonnet-4-5-20250929")base_url = os.getenv("LLM_BASE_URL")llm = LLM( usage_id="agent", model=model, base_url=base_url, api_key=SecretStr(api_key),)# Toolscwd = os.getcwd()tools = [ Tool( name=TerminalTool.name, ), Tool(name=FileEditorTool.name), Tool(name=TaskTrackerTool.name),]# Create a condenser to manage the context. The condenser will automatically truncate# conversation history when it exceeds max_size, and replaces the dropped events with an# LLM-generated summary. This condenser triggers when there are more than ten events in# the conversation history, and always keeps the first two events (system prompts,# initial user messages) to preserve important context.condenser = LLMSummarizingCondenser( llm=llm.model_copy(update={"usage_id": "condenser"}), max_size=10, keep_first=2)# Agent with condenseragent = Agent(llm=llm, tools=tools, condenser=condenser)llm_messages = [] # collect raw LLM messagesdef conversation_callback(event: Event): if isinstance(event, LLMConvertibleEvent): llm_messages.append(event.to_llm_message())conversation = Conversation( agent=agent, callbacks=[conversation_callback], persistence_dir="./.conversations", workspace=".",)# Send multiple messages to demonstrate condensationprint("Sending multiple messages to demonstrate LLM Summarizing Condenser...")conversation.send_message( "Hello! Can you create a Python file named math_utils.py with functions for " "basic arithmetic operations (add, subtract, multiply, divide)?")conversation.run()conversation.send_message( "Great! Now add a function to calculate the factorial of a number.")conversation.run()conversation.send_message("Add a function to check if a number is prime.")conversation.run()conversation.send_message( "Add a function to calculate the greatest common divisor (GCD) of two numbers.")conversation.run()conversation.send_message( "Now create a test file to verify all these functions work correctly.")conversation.run()print("=" * 100)print("Conversation finished. Got the following LLM messages:")for i, message in enumerate(llm_messages): print(f"Message {i}: {str(message)[:200]}")# Conversation persistenceprint("Serializing conversation...")del conversation# Deserialize the conversationprint("Deserializing conversation...")conversation = Conversation( agent=agent, callbacks=[conversation_callback], persistence_dir="./.conversations", workspace=".",)print("Sending message to deserialized conversation...")conversation.send_message("Finally, clean up by deleting both files.")conversation.run()print("=" * 100)print("Conversation finished with LLM Summarizing Condenser.")print(f"Total LLM messages collected: {len(llm_messages)}")print("\nThe condenser automatically summarized older conversation history")print("when the conversation exceeded the configured max_size threshold.")print("This helps manage context length while preserving important information.")# Report costcost = conversation.conversation_stats.get_combined_metrics().accumulated_costprint(f"EXAMPLE_COST: {cost}")
Running the Example
export LLM_API_KEY="your-api-key"cd agent-sdkuv run python examples/01_standalone_sdk/14_context_condenser.py
Create a LLMSummarizingCondenser to manage the context.
The condenser will automatically truncate conversation history when it exceeds max_size, and replaces the dropped events with an LLM-generated summary.This condenser triggers when there are more than max_context_length events in
the conversation history, and always keeps the first keep_first events (system prompts,
initial user messages) to preserve important context.
from openhands.sdk.context import LLMSummarizingCondensercondenser = LLMSummarizingCondenser( llm=llm.model_copy(update={"usage_id": "condenser"}), max_size=10, keep_first=2)# Agent with condenseragent = Agent(llm=llm, tools=tools, condenser=condenser)
 This approach achieves remarkable efficiency gains:
This approach achieves remarkable efficiency gains: